Measuring the quality of code in Roadkill
July 31, 2013
One of the subjects I recently studied in my part time university course was how to measure a software system’s complexity, including quality measures for your code. These are statistical ways of measuring code or system complexity date back to before the SOLID principles became popular and with a little bit of insight give a fairly good marker of how complicated or clean your code is.
With Roadkill almost 3 years old, I thought I’d give some of the metrics a try on the source. There’s basically two ways of measuring system complexity: before you start the project and after/during the project.
The “before you start the project way”
The lines of code and length of the project can be estimated before starting the project by using something known as function point analysis (FPA). For this you take the UML use-case and class diagrams you have beautifully crafted and extract an estimate of the lines of code required by measuring the inter dependencies.
(There are also other more obvious ways of doing estimates such as estimating based on previous project experience, breaking the work into smaller chunks and estimating but those techniques don’t include KLOC.)
Using the output from the FPA you can then extend the estimation further by incorporating another estimation method called COCOMO. This takes the estimated lines of code from your FPA, and based on the language you’re using produces an estimated number of man months.
For Roadkill, this would obviously be a bit pointless though as I didn’t UML diagram the project (nor should anyone doing a personal OS project in my view) or produce any big upfront design, and doing it now would be a waste of time. So that leads to the second way of estimating the system complexity.
The “during or after the project way”
The commonest way to do this is through KLOC, or thousands of lines of code. OLOH employs this technique to give a rough estimation of the size of each of its OS projects it lists. It is, however, quite a primitive way of doing things and doesn’t really give you any idea of how easy the project is to maintain, bug fix and add new features to in the future - arguably the holy grail of software development.
A texhnique called Cyclomatic-complexity is one of better and more scientific ways of measuring the complexity of your code, and dates back to before I was born. Tom Mcabe introduced it in 1976 and the idea behind it is fairly simple: count the number of branches or decision points in your methods/functions to arrive at a figure representing the complexity. So an if statement would count as 1, a while loop 1 and so on.
Object-oriented metrics also exist including DIT, CBO (coupling between objects), NOC (number of children) and probably the most useful LCOM (lack of cohesion in methods metric). LCOM is worked out by calculating the number of pairs of methods that both access a private member variable (call this A), and the number of pairs that don’t (B). You then arrive at a figure by just calculating B - A, which if it’s negative is a zero.
Of course you have to use your judgement with these metrics as this SO answer points out - they are there to provide some indication of the code complexity rather than a set of hard rules (“convert this to a constant”).
NDepend
So how does Roadkill fair with all of these metrics? Originally I set out to count a sample of classes in the Roadkill.Core project and get some metrics including KLOC. Luckily as I finish writing this blog post NDepend provided me with a free licence for Roadkill as an OSS project freebie.
As a lazy programmer (the good type) I’m a sucker for productivity tools so I set about getting graphed-up on the Roadkill source. NDepend includes all the during/end of project metrics I’ve listed plus a whole host of its own that are specialized ones for. NET.
The LINQ statements I used for my stats were:
| // <Name>LCOM</Name> | |
| from t in JustMyCode.Types where t.LCOM > 0 | |
| orderby t.LCOM descending | |
| select new { t, t.LCOM } | |
| // <Name>LOC</Name> | |
| from a in JustMyCode.Assemblies | |
| select new { a, a.NbLinesOfCode, a.NbILInstructions } | |
| // <Name>Cyclomatic complexity</Name> | |
| from m in JustMyCode.Methods | |
| where m.CyclomaticComplexity > 0 | |
| orderby m.CyclomaticComplexity descending | |
| select new { m, m.ParentType.Name, m.CyclomaticComplexity } |
First off KLOC:
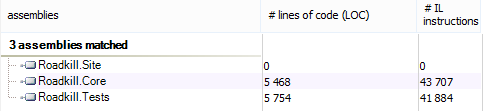
This demonstrates that I have as much test code as I do production code (minus the HTML views, Javascript, CSS) which would no doubt horrify older school purists and coders who don’t embrace TDD or unit testing. For me it feels like a good sign though - I know I have fairly complete test coverage for the project, with the main gaps coming from wiki markup parser, which I use a Microsoft OS project for and the logging and caching.
Next up is Cyclomatic Complexity (I’m counting anything with over 3 decision points):
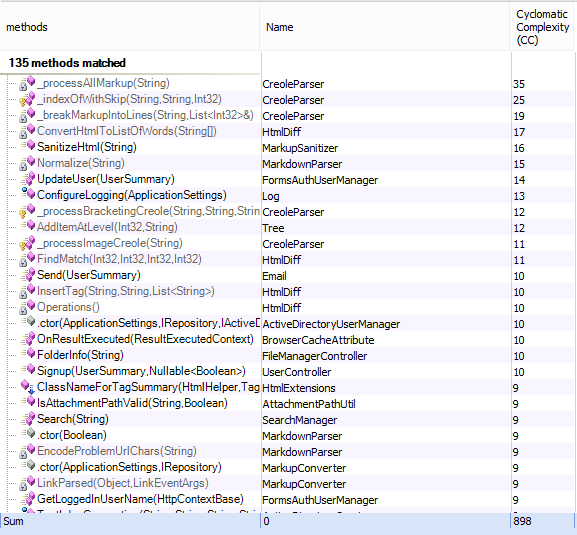
The results are actually mostly positive, the majority of problems come from the CreoleParser class which came from creoleparser.codeplex.com, with some adjustments added to it over time. I’m looking to replace this completely in version 2 with an ANTLR based approach.
One surprise from the table is that the Dependency Injection container - essentially the root or entry point of the application - is missing. It’s the “smelliest” class in the project and contains reams of hard to read Structuremap configuration.
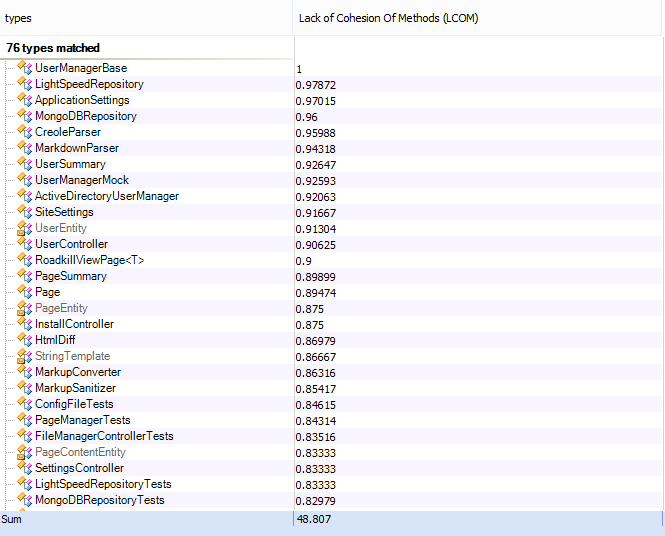
Finally there are the LCOM results - everything with 1 or above. Back in version 1.4 this would been a lot different as the project was riddled with poorly designed singletons I’d used as a deliberate design decision to make an API that was easy to use. Unfortunately it made the source very un-testable and involved a huge refactor to constructor injection to get rid of it.
Higher LCOM values can mean you are calling static methods variables on other classes but there are no classes with more than a 1 LCOM in version 1.8, which is nice:
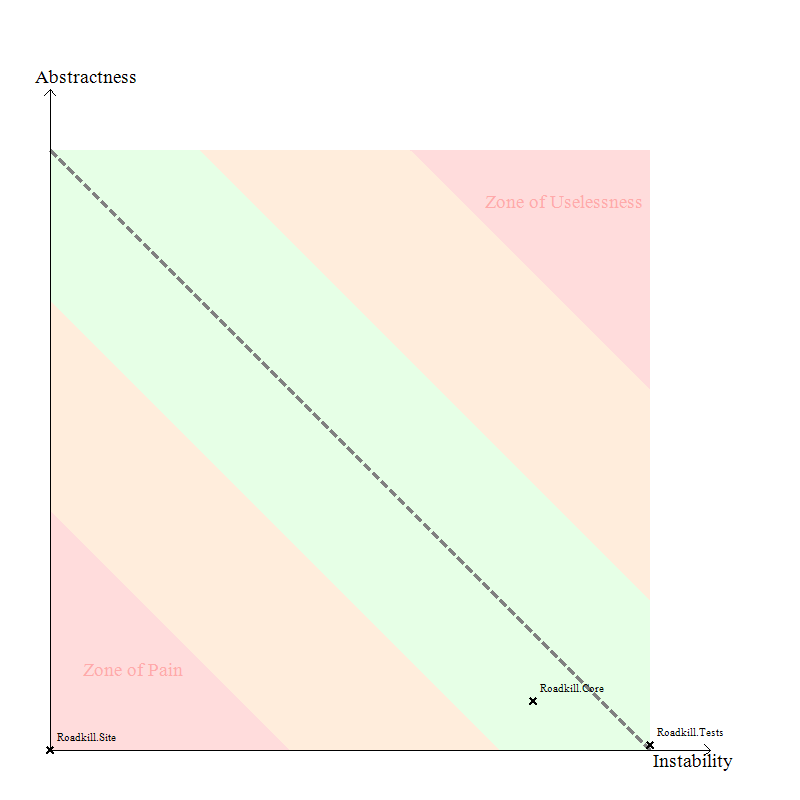
And in summary NDepend thinks the project is green, though a bit too close to unstable:

I'm Chris Small, a software engineer working in London. This is my tech blog. Find out more about me via Github, Stackoverflow, Resume