Object, Donut, OutputCache and Browser Caching in ASP.NET MVC
April 15, 2013
I’ve spent the last week working on sorting out the caching in Roadkill as prior to 1.6 it relied on NHibernate’s second level in memory cache and some incorrect 304s.
Roadkill now has 3 levels of caching:
Outputcache/donut caching
This is caching the view result aka the HTML output and returning it, to save the overhead of the view engine running. I’ve permanently disabled this for now as it was a bit of a premature optimisation until Roadkill installs are done for large sites. There’s an MVC donut caching package which allows you decorate actions with an attribute to set them as cacheable, but unfortunately it returns straight away from the action, which meant it couldn’t be used with the other existing attributes in Roadkill.
The razor view engine can already handle 1000s of requests per second on a standard server, so it won’t be a major bottle neck. There’s a number of other optimisations that also be done, such as disabling the other view engines, but in reality browser caching combined with modern fast connections make this a bit redundant until Roadkill hits Wikipedia’s page view count, which will probably be never.
Object caching
The new ORM I’ve switched to, Lightspeed, has second level caching built in, but I’ve put an in-memory cache layer after it in the ‘service’ layer, so that when you’re not logged in all pages have their markdown transformed into HTML and then thrown into the cache. The cache uses the System.Runtime.Cache so can be scaled up to a distributed cache like Azure or Memcached at any point.
Browser Caching
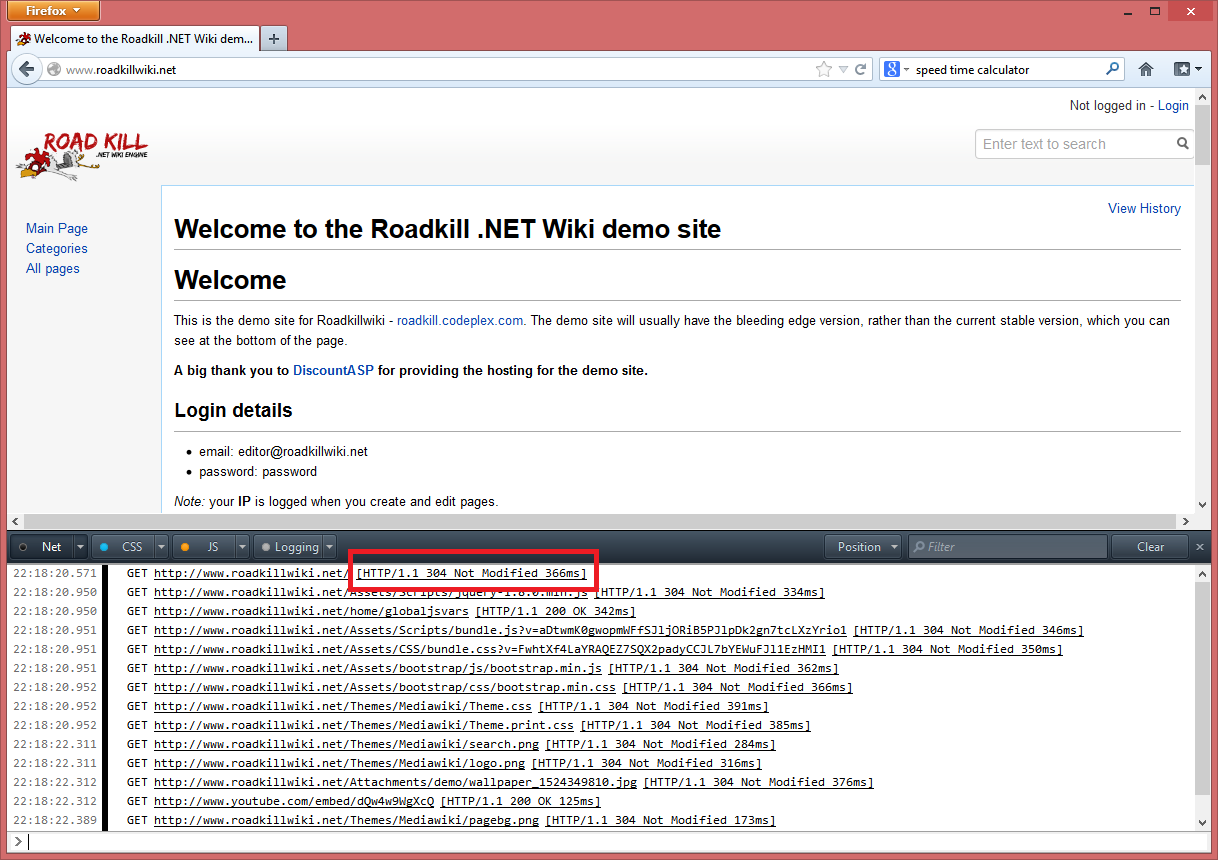
This is where I learnt a lot about client-side caching, specifically in conjunction with MVC. Roadkill version 1.5 and earlier added a if-not-modified header check but I discovered how it was doing it was completely wrong. There are basically 3 variations of browser caching you can do, which aren’t mutually exclusive:
Url based with expires
This is where you add a ‘thumbprint’ to the file or resource, for example appending a timestamp to the end of a filename or onto a querystring after the file. This is then combined with a strict cache header.
Time/date based expiry (strict header)
To make url based caching have any effect, your pages or files need to set one of the two possible expiry headers: max age or expires. These are known as strict cache headers as the browser is meant to obey them or risk being put in the naughty corner. Expires is a date in the future the resource is due to expire, in an ISO format. Max-age is an alternative and is seconds in the future. You’re not meant to set an expiry date of over a year, and as far as I can tell modern browsers support both equally well.
Etag and If modified since (loose caching)
Obviously once you set a resource to expire in the future, you can’t then force the browser to refresh without asking the person using the browser to clear their cache. Using a thumbprint in your url is one way around this but is only really practical if you can dynamically generate file names, and Google reports that it also causes 404s and cache problems with older versions of Squid, which is the most popular cache server that a lot of ISPs use.
The smart alternative is to set your expires or max-age header to a date in the past, and check the resource date on the server on every request. This is how Roadkill does it, by returning a 304 HTTP status code if the content hasn’t changed. One caveat to doing this is to make sure you also set the content length to zero or the entire file content (payload) is sent back. In MVC the HttpStatusCodeResult does this for you.
There are two ways of letting the browser check the freshness of the resources: using etags and using last modified headers. The Google page linked at the bottom has more info on this, but in summary the etag technique requires a unique hash for the resource which would change each time the file changes, making a date slightly more efficient for larger files and pages as you’re not having to calculate any type of MD5.
The overhead of this 304 method is the browser still has to make server requests, however the server only gets bytes of data (just the header) rather than the full content. You get greater control and ensure your site is always fresh at the expense of more requests from the browser, which is exactly what’s need for lower page view wikis and CMSs.
If you’re guaranteed not to change the site more than once a day, week, month then obviously the strict caching methods is better suited. One feature I’m hoping to add to Roadkill in the future is for users to be able to set expiry dates on pages, as an advanced feature you can switch in.
If you’d like to see the caching in action in Roadkill, the source code files are here.
Most of the information on browser caching is from this excellent Google guide, and the HTTP RFC

I'm Chris Small, a software engineer working in London. This is my tech blog. Find out more about me via Github, Stackoverflow, Resume